We have been sitting on a hidden genetic treasure waiting to be unearthed – It is buried in the masterpieces of past authors such as Shakespeare, Dante, and Dickinson. And I believe I have found a way to get it, to unveil literature’s genetic code. Several years ago, after visiting a museum in London, I bought Uncreative Writing by Kenneth Goldsmith — Context is the new content is the mantra of that book. Inspired by this and by applying bioinformatics to literature, I have discovered William Shakespeare’s DNA and other genetic treasures.
At that time, my scientific research was focusing on the bioinformatic analysis of all known protein structures. I wanted to find out whether a novel kind of chemical interaction called anion-π exists in biological systems.
My colleagues thought that I was wasting my time. It is science fiction, they would say.
After a while, my article Recent Advances in Anion–π Interactions got published. That work is the first study that indicates the existence of those weak forces in biological structures.
It was then that, inspired by Goldsmith’s context is the new content, I asked myself: What happens if I apply bioinformatics to literature?
On that day, my #Biotext was born.
What The Heck Is bioinformatics?
Bioinformatics is a meta-discipline that provides computational tools to navigate the gigantic amount of information produced in the biological field like, for instance, DNA and protein X-ray structures. With these tools, one can seek, analyze, and compare large sets of data such as strings of text that carry biological information — Funny enough, bioinformatics is not that different from the Digital Humanities.
What if you replace those biological strings with literary strings?
How I discovered Shakespeare’s DNA
Let’s start with Shakespeare’s Macbeth Act 5, Scene 5:
Life’s but a walking shadow, a poor player,
that struts and frets his hour upon the stage, and then is heard no more;
it is a tale told by an idiot, full of sound and fury, signifying nothing
Now, notice the A G C T letters. These are not standard letters as they also represent the nucleobases Adenine, Guanine, Cytosine, and Thymine of the DNA helix:
Life’s buT A wAlkinG shAdow, A poor plAyer,
ThAT sTruTs And freTs his hour upon The sTAGe, And Then is heArd no more;
iT is A TAle Told by An idioT, full of sound And fury, siGnifyinG noThinG
If you align them in a row, magic happens! You have just obtained a short DNA single strand.
TAAGAAATATTTATTTAGATATATATATAGGTG
Wait… it gets better!
Let’s say that you collect all 39 plays, 154 sonnets, and everything else that Shakespeare has written, you order all this text chronologically, then use a simple algorithm to extract the letters A G C T, and voilà: You get the Genetic Code of William Shakespeare — A document that contains more than 80.000 letters, all carrying a biological information.
This genetic masterpiece looks like this:

Visualizations of genetic masterpieces
Once you have a genetic code, you can do all sort of marvelous things with it. For example, you can predict, analyze, and visualize its structure.
You may extract a single DNA strand from Emily Dickinson’s poem Almost! and combine it with its complementary DNA strand. Each G corresponds to a C and each A to a T (and vice versa). This is the so-called Watson-Crick pairing. Having obtained a double helix sequence, you may build its spatial coordinates and visualize them with available software like VMD.

We are having fun, aren’t we?
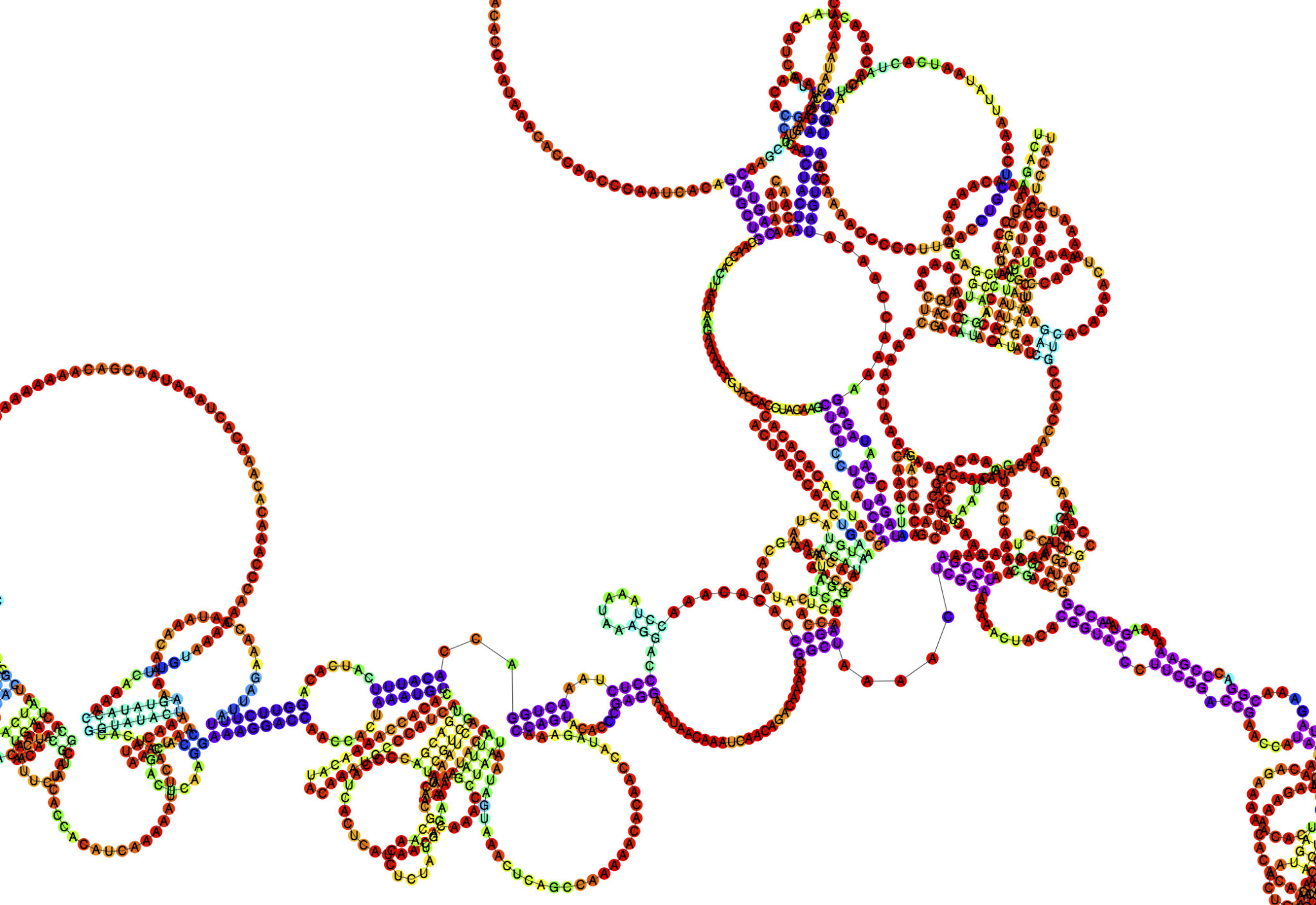
We can do the same with RNA. For instance, you may extract an RNA single sequence from Dante’s Inferno and then use RNAfold to predict and visualize its 2D RNA structure.
My RNA Infernal Structures have been published in Canada as part of Derek Beaulieu’s book series of visual poetry.
Isn’t this beautiful!?
As mentioned, if you have a genetic code, you can also visualize its 3D structure.
The following is the 3D DNA structure of the incipit of Cesare Pavese’s masterpiece La Luna e i Falò:
Literature’s genetic code: what’s the point?
My #Biotext is a by-product of the digital world in which we live. It brings together three elements: a simple analysis of Big Data (thousands and thousands of lines of text), 2D/3D visualizations, and Kenneth Goldsmith’s context is the new content.
In my opinion, the mere idea of applying simple bioinformatics tools to literature is intriguing. Besides, making use of scientific analysis to uncover literature’s genetic code, it is a delightful divertissement.
If it is true that literature is not a sum of single pieces, but rather a collective system that needs to be understood as a whole, then we may stretch this concept and go as far as to say that literature is a living system.
And now with #Biotext we also know how to extract and visualize its genetic code.