A few years back, my artistic side led me to the pages of a Canadian visual poetry catalogue. The title of my creation? Dante’s RNA Infernal Structures, a unique piece of my quirky project, #BIOTEXT. At that time, as I was learning some bioinformatics tools for my research on anion-π interactions, an idea struck me: why not apply bioinformatics to literature as well? The end result was quite impressive, if I may say so myself. But let’s be real: While #BIOTEXT was an artistic experiment, scientifically speaking, RNA structure prediction – predicting the structure of RNA from its sequence – remains a substantial challenge. Now, with the recent buzz about AlphaFold revolutionizing protein structure prediction, it begs the question: When will RNA experience its AlphaFold breakthrough? Can we predict RNA structures from their sequences with a degree of confidence? So, buckle up. Today, inspired by Schneider‘s recent article in Nucleic Acids Research, we’re going to tackle this big question head-on.

Why does RNA structure prediction matter?
When I think of RNA and its multitude of functions, I picture a bustling city within the cell, where RNA acts as the diverse workforce powering that metropolis. Now, one of RNA’s most striking roles is in translation. Here, the assembly of proteins is meticulously coordinated by ribosomal particles, with ribosomal RNA performing the crucial catalytic step, aided by transfer RNAs that precisely deliver amino acid residues.
RNA is also a master of regulation. Among the various RNA types, a significant portion is indeed noncoding RNAs. But the significance of RNA extends even further. In the grand scheme of life, particularly in organisms like HIV and other viruses (since when are viruses living organisms?), RNA serves as the primary genetic storyteller – not DNA.
So, how does RNA choose one function from its myriad of options? Well, it almost entirely comes down to its secondary structure.
RNA is a mesmerizing landscape of complex chemistry and intricate architecture. Each RNA strand is a sophisticated arrangement of nucleotides – tiny molecular structures made of sugar rings, phosphate groups, and four nucleobases. Three of these are shared with DNA (cytosine, guanine, adenine) and one, uracil, is unique to RNA. These components come together thanks to a chemical interplay of van der Waals interactions and hydrogen bonds.
But keep in mind, the structure of RNA isn’t a random tangle; it’s a well-orchestrated system of shapes and charges. The phosphate groups add, quite literally, their own twist to the mix. These negatively charged moieties need partners – positive ions – to maintain balance. Since the oxygen atoms in these phosphates are highly polarizable, they can engage in a variety of interactions. These include hydrogen bonds with other RNA atoms, proteins, and water to charge-charge interactions with amino acids and other cellular components like amines, and even metals.

Think of the primary structure of RNA like a sequence of characters in a story – four nucleotides spelling out life’s instructions (A, G, C, U). The secondary structure? That’s where the story unfolds. It refers to the planar structure formed by the interaction and folding of non-adjacent bases. We’re talking about hairpin loops, bulge loops, inner loops, multi-branched loops, single-stranded regions, helices, and pseudoknots – the seven recognized secondary structural elements.
The cool thing is that an accurate prediction of RNA secondary structure is a strong guarantee for the determination of RNA tertiary structure, its 3D folding in space. Moreover, numerous experiments have shown that RNA secondary structure is closely related to its function.
And that’s why we are so keen on predicting RNA structure. Simply put, RNA plays a central role in the intricate machinery of life and its specific functions are intrinsically linked to its structure.
In other words, predicting RNA structure from its sequence is like deciphering life’s very blueprint. This isn’t just a cute metaphor – it’s a gateway to shed light on the RNA world hypothesis or to potentially develop and fine-tune revolutionary RNA-based therapies.
So, we’ve mastered predicting protein structures from their sequences, right? Can we now replicate this success with RNA structure prediction?

More on From Atoms To Words:
▸ 60 Years in the Making: AlphaFold’s Historical Breakthrough in Protein Structure Prediction
▸ AI in Drug Discovery: Chasing Dreams, Facing Realities
▸ All-Atom Molecular Dynamics of SARS-CoV-2: The Computational Microscope’s View of 305 Million Atoms
RNA structure prediction: A Leap Through Time
Rewind to the 1960s, and picture a world where the quest to predict RNA structure was just beginning to take shape. Scientists, armed with sequence homology and a hefty dose of computational ingenuity, embarked on their pioneering in silico journey, manually assembling the pieces of the RNA puzzle.
Fast forward to the brink of the new millennium, 1998 to be precise. It’s a pivotal year for RNA structure prediction as it marked the debut of the first interactive tool for RNA structure modeling: Massire and Westhof’s MANIP. It was like the first brushstroke on a blank canvas, paving the way for potential breakthroughs to come.
As we journeyed through the 21st century, the RNA structure prediction landscape underwent a significant transformation, with more sophisticated tools emerging left and right. These tools, both fully and semi-automatic, breathed life into RNA sequences, morphing them into 3D models. There were the trailblazers like FARFAR and iFoldRNA, which sculpted structures from scratch (ab initio), while others like RNABuilder and ModeRNA took cues from existing data, employing homology modeling.
But the real seismic shift? It has occurred in the last couple of years – a period where deep learning has taken center stage. This is where the story takes a thrilling turn. Townshend et al.’s work is a prime example, showcasing how deep learning can assess the quality of newly generated RNA structures, alongside other comprehensive prediction methodologies
This evolution of technology, from the manual models of the ’60s to today’s sophisticated deep learning systems, shows just how tirelessly we’ve chased a solution to the RNA structure prediction challenge.
How far have we come with RNA structure prediction? And how much further do we still need to go?
Further reading: When will RNA get its AlphaFold moment? | Schneider, 2023
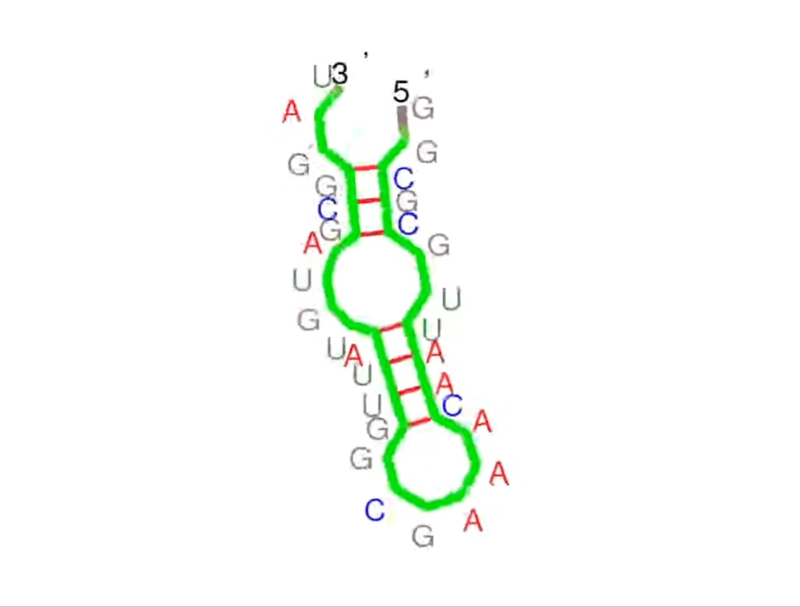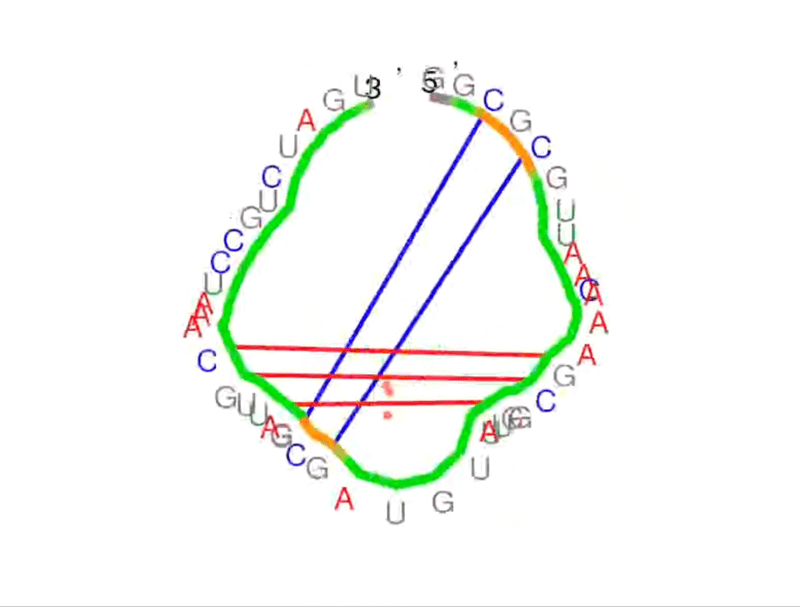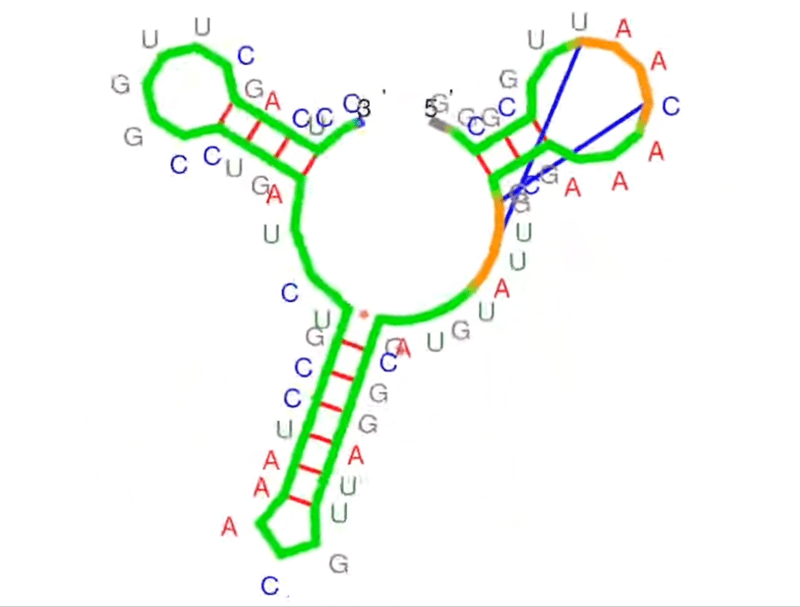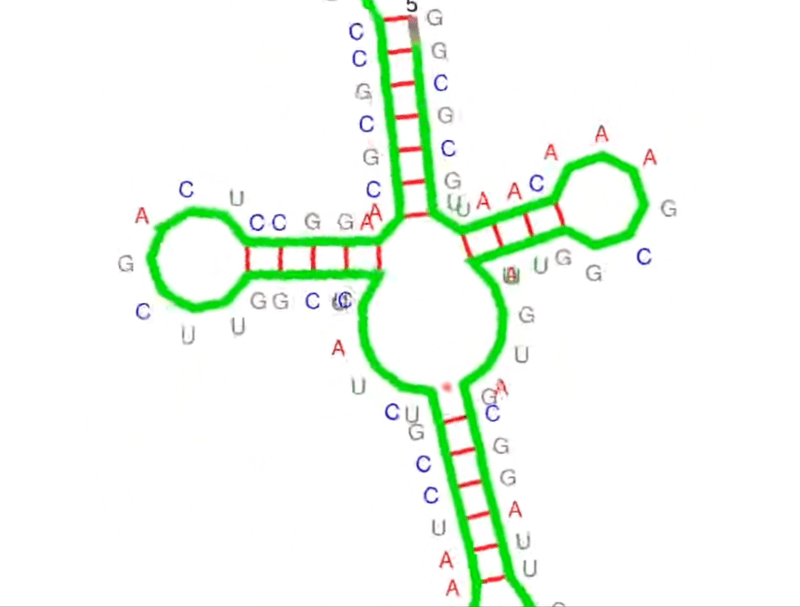
More on From Atoms To Words:
▸ Large Language Models for Chemistry: Is the Beginning of a New Era?
▸ 7 Noncovalent Interactions in Proteins: The Hidden Architects of Structures and Functions
▸ Water’s Hydrogen Bonds: What Makes Them Vital for Life As We Know It?
RNA Structure Prediction: Where are we Today?
Remember CASP, the biennial competition where researchers are invited to take part in a blind test to predict protein structures? In the RNA world, something similar exists: It’s called RNA-Puzzles. How does it work? Participants get the sequence of an RNA molecule that’s already been mapped out but isn’t public yet, and their challenge is to predict its structure using various computational techniques.
Since 2010, RNA-Puzzles has significantly influenced the field of RNA structure prediction. This initiative has evolved, embracing the advent of deep learning methods and widening the horizon for RNA modelers, a shift highlighted by the CASP-RNA contest of 2022.
But how do they verify the validity of a prediction?
Central to the assessment of RNA structure prediction models are specific metrics, fine-tuned to the unique characteristics of RNA. A standout in this evaluation toolkit is the Interaction Network Fidelity (INF), where INF = 1 signifies ideal prediction and 0, well, total failure. This metric indicates the accuracy in predicting base pairs, encompassing both the standard Watson–Crick pairs (INF-WC) and the more elusive non-Watson–Crick interactions (INF-NWC), as well as stacking arrangements (INF-stacking).
So, how confidently can we predict the RNA structure?
While INF-WC scores have been promising, often ranging between 0.75 and 1.0, the challenge emerges with the prediction of non-Watson–Crick base pairs, where INF-NWC scores tend to be worryingly low.
This is indeed concerning, since the non-Watson–Crick base pairs guide packing and junction topologies, playing a crucial role in determining the overall fold of the RNA.
I must admit, the conclusion is somewhat disappointing. Despite considerable advances in modeling, accurately predicting the RNA structure is still an enormous challenge and requires significant improvements in both accuracy and quality.
But why exactly is RNA structure prediction such a daunting task? Why don’t we already have an AlphaFold for RNA?
Further reading: When will RNA get its AlphaFold moment? | Schneider, 2023
The Data Conundrum in RNA Structure Prediction
A machine learning model is only as good as the data it’s trained on. So, it’s thanks to the significant amount of information available in the protein data bank that AlphaFold nails the prediction of protein structures from amino acid sequences.
Like Americans say, AlphaFold is a home run.
Switch gears to RNA structures, and researchers find themselves in a bit of a pickle. The data set for RNA is small compared to proteins, is highly biased, and the existing alignments have some shortcomings.
Curious about the details? Let’s dig in:
- Database Disparity: In the protein data bank, RNA presence is tiny when you stack it up against proteins – think a 1 to 25 ratio. The root of this massive underrepresentation? It’s all about RNA’s natural flexibility. And if we zoom in on just high-resolution data, the picture gets even bleaker, with the ratio widening to a whopping 1 to 100. This is a major stumbling block because it’s these high-quality structures that feed the most dependable data into machine learning models for predicting RNA structures.
- Quality Issues: Now, let’s talk about a real headache in RNA research – the quality standards, or rather, the lack of them. There’s no one-size-fits-all rulebook for RNA data quality, and that’s stirring up trouble. We’re seeing mismatches in base pairing, valence geometry, and backbone geometry across different platforms. All this leads, well, to serious inaccuracies.
- Sequence and Alignment Challenges: Another obstacle for machine learning models is crafting comprehensive RNA alignments. The process is often manual, which means we’re not getting as much variety as we do with protein alignments. This shortage of diverse data, plus some existing biases in RNA alignments, really throws a wrench in the works for developing versatile machine learning models aimed at RNA structure prediction.
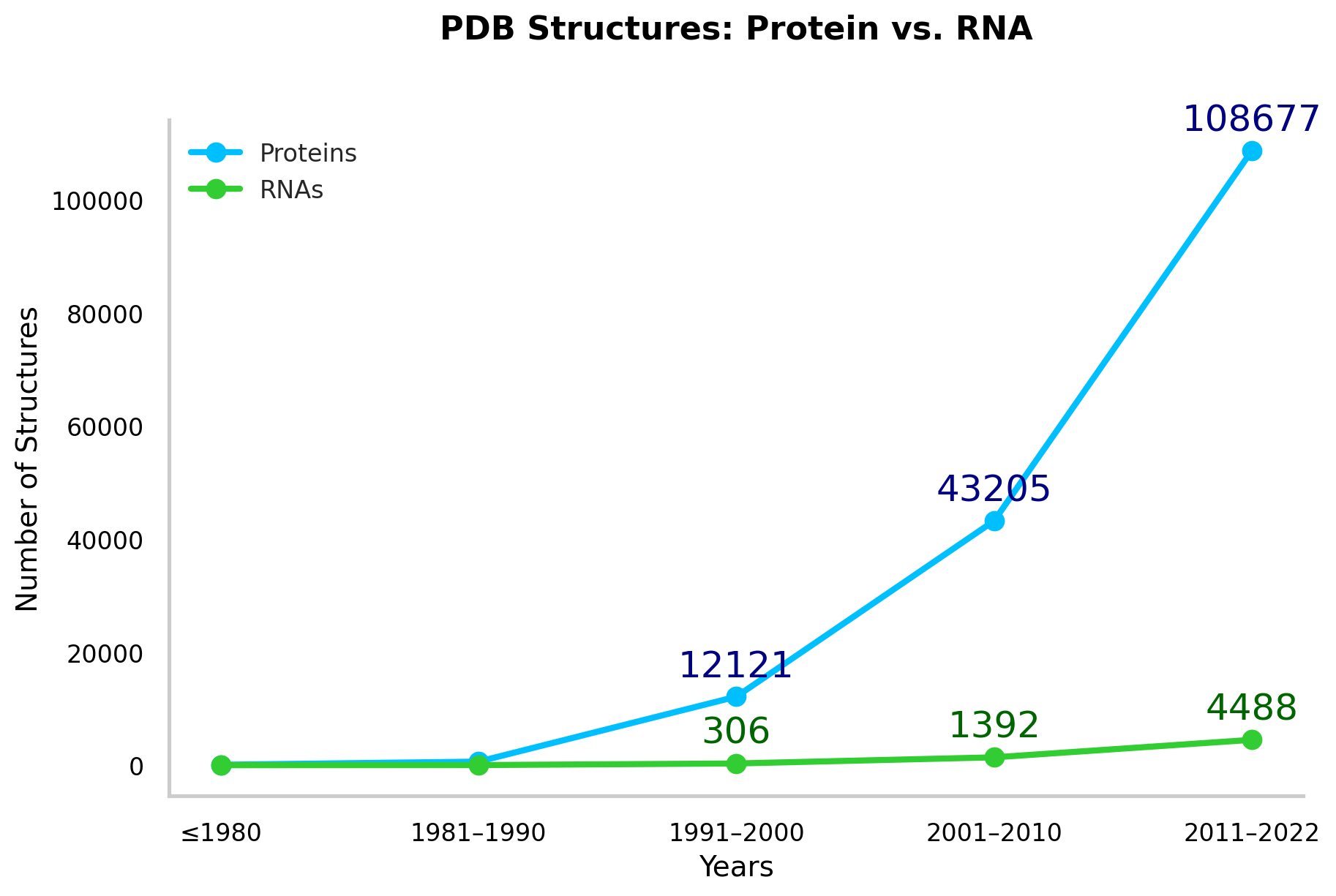
And so, our mission to decode RNA structures using machine learning is a trek through a maze of complications – think limited data, quality issues, and the intricate design of RNA itself. These hurdles outline the cutting edge of molecular biology, where the goal is not only to map out RNA structure but also to unlock the vast potential hidden within its folds.
More on From Atoms To Words:
▸ Is Machine Learning Going to Replace Computational Chemists?
▸ From Earth to the Cosmos: How Hydrogen Bonds Shape Life
▸ The Evolution of Quantum Chemistry: From Pencil and Paper to Quantum Computing
A final personal touch
Remember our story about AlphaFold‘s huge leap in predicting protein structures? I’ve had a go with it, and honestly, it’s a scientific wonder. This made me think: when’s RNA going to have its AlphaFold moment? In search of an answer, I stumbled upon the insightful article by Schneider and colleagues, which in turn inspired this very blog post.
Now, Schneider and the team offer a somewhat sobering perspective. Their approach? To look at when RNA data will catch up to protein data. Take Pfam, for example – it’s packed with around 19,000 protein sequence alignments, according to Schneider. But RNA? That’s a different story. Rfam, its RNA counterpart, sees a yearly linear growth, adding roughly 205 alignments annually. So, doing the math, we might be looking at a 70-year wait to reach those numbers.
70 years! Can you believe it?
But, there’s a silver lining. Schneider points out a few ways to speed things up. More data on RNA structures, for starters, then diversifying the data used in predictions, and enhancing the machine learning methods to deal with low-data scenarios.
Sounds like a plan, right? Well, it’s a very ambitious plan that requires a ton of work.
So, to answer the question we’ve been asking today, when might we see an AlphaFold for RNA structure prediction? One day, probably. And perhaps sooner than 70 years, if we put our minds to it.
I stay optimistic. If there’s one thing I’ve learned from the history of science, it’s this: scientists love a good challenge, no matter how impossible it seems.
If you enjoyed this dive into RNA structure prediction, I’d love to hear your thoughts. Agree, disagree, or have a totally wild theory of your own? Let’s connect! Subscribe to my LinkedIn newsletter and let’s keep the conversation rolling.